

Managing AI spend: a primer for CFOs of Enterprise RIAs
About the author: Danny Shannon is co-founder and CTO of Impruve. Before co-founding the firm, he built and managed enterprise-grade AI software data projects at J.P. Morgan Chase, built custom solutions for Options Clearing Corporation (via Maven Wave Consultancy), and led engineering at a tier-1 VC-backed AI startup, Otter.
This is a primer for CFOs of wealth management firms on the layers of cost in AI deployment and the fundamentals of managing that spend.
Most of the public conversation about AI cost focuses on tokens. In fact, in the technology world, we recently experienced a phase of “tokenmaxxing” (which is now course-correcting) in which venture investors and engineering leaders treating token consumption as a proxy for how AI-forward a company is, with a heavy push to spend more on tokens as a sign of healthy adoption. That framing is a vanity metric which measures activity, not value. And it’s certainly the wrong metric for an RIA to emphasize. Spending more on tokens without a clear line to advisor productivity, client outcomes, or revenue is just burning cash with better branding.
Additionally, in a heavily regulated environment like wealth management, the cost of deploying AI extends well beyond the model itself. You can't just adopt an off-the-shelf tool and call it done. Regulatory constraints require infrastructure work that isn't always obvious. Vendor sprawl creeps up faster than expected. The organizational cost of actually getting your team to adopt new workflows is often the largest hidden line item.
What follows is some mental scaffolding we find useful at Impruve for the categories of likely AI spend at an enterprise RIA, along with practical guidance on how to control that spend as you measure it against an ROI rubric that's still actively evolving.
Where AI ROI stands today
Measuring and overseeing AI Spend, ROI, and Governance Precautions is not as simple as placing advisors in the role of shopping for AI point solutions. As stated in McKinsey’s 2026 Study, US wealth management in 2035: A transformative decade begins:
“Teams of AI agents that executed complex workflows not only resulted in productivity improvements but also could potentially increase growth by more than 10 percent.
Our research shows that value comes not from deploying isolated agents, but from redesigning cross-functional priority workflows, building reusable agent components, and orchestrating human-agent teams at scale. For a wealth firm, this means not just giving an AI tool to an advisor, but embedding intelligent agent teams into the advisor-client journey. Reimagining and rearchitecting workflows will likely extend through client onboarding, portfolio rebalancing, tax event modeling, and even life-stage transitions, and so will entail bold decisions.
The transformation road map should detail the build, buy, and partner approach; governance implications; and change management interventions to ensure uptake of new solutions. The technology and data backbone should involve modular, API-based architectures that connect wealth legacy systems with new digital platforms. A unified, governed data model (anchored in a single source of truth for client, product, and operational data) would be required to ensure explainability, security, and reusability of any AI analytics and workflows.”
With that in mind, I like to consider this through a “layered” lens.
The five layers of AI cost
Every AI deployment at an Enterprise RIA touches five layers of cost. We've found this framework useful for organizing the conversation between technical teams and the CFO's office, because each layer has distinct cost dynamics and distinct levers for control.
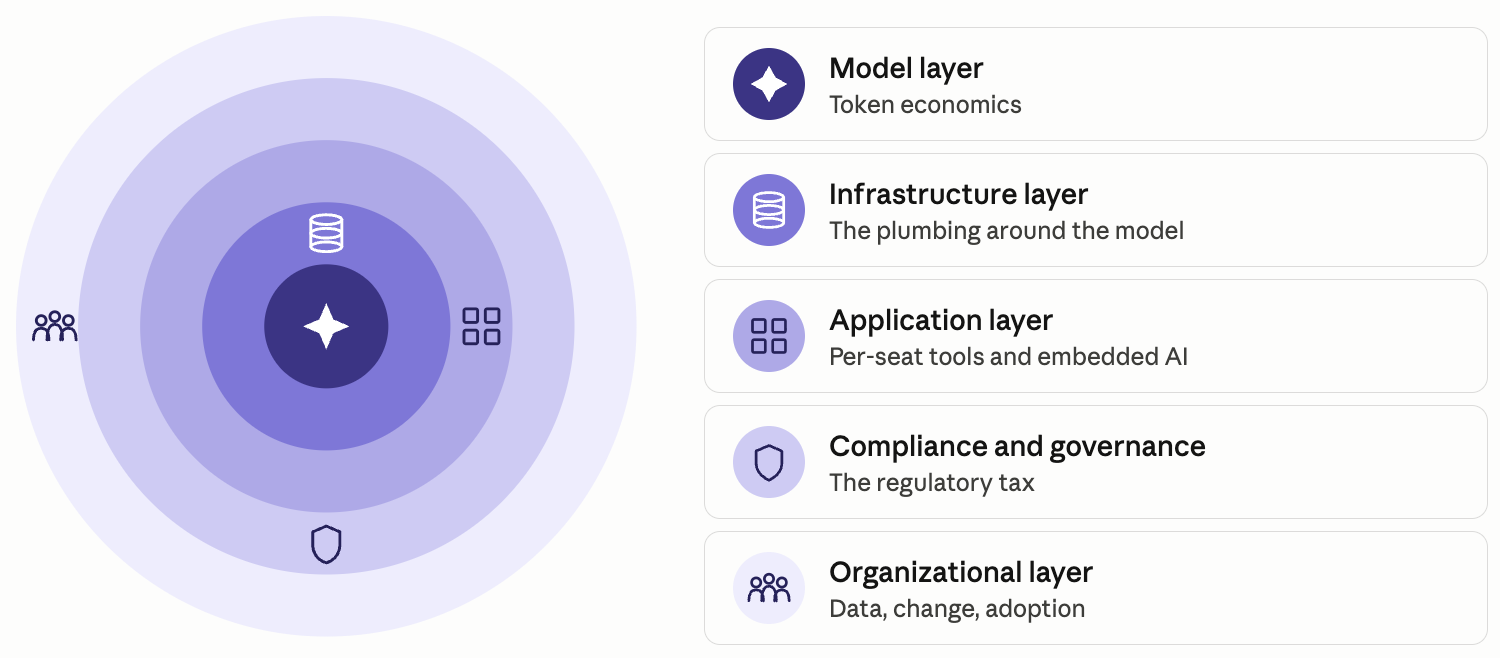
Diagram showing five layers of AI cost: model, infrastructure, application, compliance and governance, and organizational.
The model sits at the center because it's the most concrete and most discussed layer. The rings around it grow with deployment maturity, and the outermost layer (organizational) is usually the largest hidden cost. It's also the determinant of whether anything else generates ROI.
Layer 1: The model layer
The model layer is the cost of inference, or the actual process of an AI model thinking and responding to a request. Every time a model reads input and generates output, you're paying for tokens, the small chunks of text (roughly a word or word-fragment each) that models use to measure both what they read and what they write. It’s beneficial for CFOs to understand the core tenants of token cost in order to ask the right questions internally to ensure that your RIA’s overarching AI infrastructure controls against any runaway spend.
In a later write-up, I’ll dive deeper into “tokenomics”, but for an initial primer in this piece, token types can be broken down as follows:
| Cost Type | Description | Sonnet 4.6 Price (per 1M tokens) |
Pricing Relationship |
|---|---|---|---|
| Input tokens | Everything sent to the model: system prompt, conversation history, user message, attached documents. | $3.00 | Base input price. |
| Output tokens | Everything the model generates back. | $15.00 | 5x input price across every Claude model. |
|
Cache write tokens (5-minute) |
First time storing a chunk of input for reuse in the 5-minute cache. | Roughly $3.75 | 1.25x base input price. |
|
Cache write tokens (1-hour) |
First time storing a chunk of input for reuse in the 1-hour cache. | Roughly $6.00 | 2x base input price. |
For an example as of this writing:
These costs are for tokens per 1 million tokens across the current Claude lineup:
| Model | Input Cost ($) | Output Cost ($) | Cache Read Cost ($) |
|---|---|---|---|
| Claude Haiku 4.5 | 1.00 | 5.00 | 0.10 |
| Claude Sonnet 4.6 | 3.00 | 15.00 | 0.30 |
| Claude Opus 4.7 | 5.00 | 25.00 | 0.50 |
Say you send a 10,000 token request to Sonnet 4.6 and get back a 1,000 token response with no caching:
Input: 10K × $3/M = $0.030
Output: 1K × $15/M = $0.015
Total: $0.045
Now imagine that 10K input is mostly a fixed system prompt you're reusing across 100 calls. Cache it once, and the next 99 calls only pay $0.003 each on input instead of $0.030. That's where material savings show up.
The CFO Question() to ask:
How is our team optimizing for efficient token use?
The Answer to look for: The biggest levers are prompt caching, batch processing, and model routing. Caching reused context (system prompts, reference documents, client briefs) can cut input costs by up to 90 percent. Batch processing for non-urgent work runs at half the standard rate. And “model routing” (sending simpler tasks to a smaller cheaper model while reserving a flagship model for complex reasoning) can meaningfully reduce spend without sacrificing quality where it counts.
When using a platform like Claude or ChatGPT directly, much of this is handled for you: modern models already adapt their reasoning to task complexity, and the platform manages caching behind the scenes. However, when building custom workflows, these levers become available directly and need to be understood. These are the levers a competent technical team should be pulling, and the CFO should be able to ask about them in plain language.
In the typical AI Architecture that Impruve helps RIAs build, this occurs at the “Orchestration layer”:
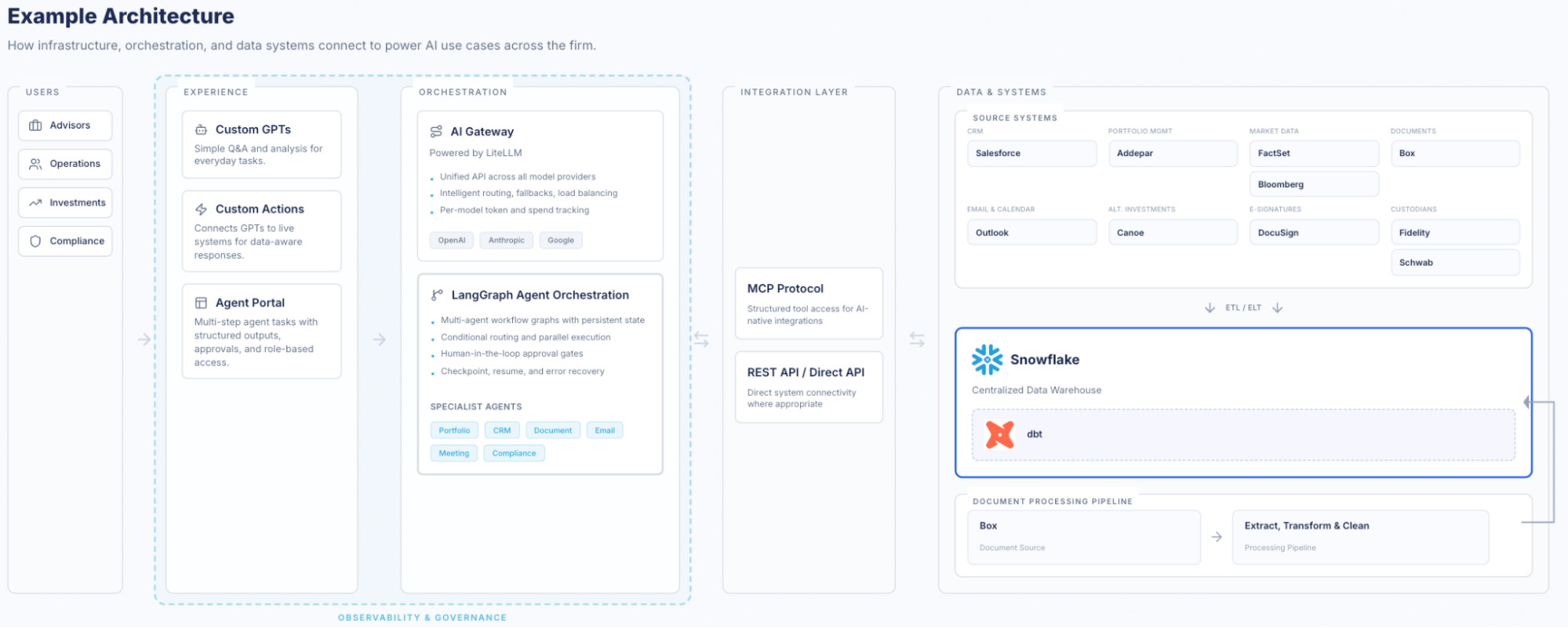
Diagram showing an example AI architecture connecting users, experience layers, orchestration, integration layers, and data systems across a firm.
A word of caution: One risk here is over-optimizing. Aggressively cutting tokens or routing too many tasks to lesser models often leads to worse output quality and a degraded user experience. Get the fundamentals right (caching, batching, smart model selection) and then focus your energy on the quality of what the AI is actually producing.
Layer 2: The infrastructure layer
This is the plumbing around the model. It includes the orchestration and gateway layer (which is where most of the cost levers from Layer 1 actually get implemented), vector databases for retrieval, embedding models for search, observability and logging tools, and the integration middleware that connects AI to the firm's existing systems: CRM, planning software, custodian feeds, document management. Not all of these are required for every use case, as the right stack depends on what you're actually building.
This layer tends to surprise CFOs, and some parts of it are prone to be over-sold by large consultancies. For example, as Impruve’s Chief Data Officer Jordan Campbell recently wrote about, not every RIA necessarily needs to incur the cost of expensive data lake / warehouse management. It all depends on what outcomes you’re aiming to achieve with your firm’s AI strategy.
The CFO question(s): what does our orchestration architecture look like, and is it set up to give us flexibility across model providers? Do our use cases require full data lake/warehouse management, or can we achieve our objectives with other means such as just-in-time data inputs?
Answer to look for: Portability matters here. If everything is locked in one vendor, you have less leverage in pricing conversations and more risk if a provider changes terms. A gateway layer (LiteLLM, OpenRouter, or internally built) gives you the option to swap models, route by cost, and observe spend at a granular level. This is the layer where good architectural decisions early compound into real savings later.
Layer 3: The application layer
This is the per-seat SaaS surface. Claude for Enterprise, ChatGPT Enterprise, Microsoft Copilot, plus the AI features your CRM, planning software, meeting notetakers, and document management vendors are now charging for as add-ons.
For most RIAs that haven't built heavy custom workflows yet, this layer is the largest AI line item. It's also where vendor sprawl shows up first and most visibly.
The CFO question: where do we have capability overlap across our AI tool stack?
Answer to look for: We recommend a vendor map review at least annually, with a forcing function to consolidate where capability overlaps exceed a threshold the firm sets in advance. The discipline is to make any new AI subscription justify itself against what's already in the stack.
Layer 4: The compliance and governance layer
This is where highly regulated industries must be especially careful and an often overlooked area of the budget.
What lives here: SEC marketing rule review for AI-generated content that touches client communication, books and records retention requirements for AI-influenced communications, vendor security and SOC 2 diligence, data processing agreements, training opt-out verification (you do not want client data flowing into model training sets), E&O and cyber insurance adjustments, supervisory framework updates, and audit trail capabilities for every AI workflow that touches a regulated function.
This is best understood as a preventative cost. It's what you pay to avoid a much larger cost downstream. In a heavily regulated space where frontier AI capabilities are emerging faster than regulatory guidance is being published, the risk is real and the audit trail is what protects you.
The CFO question: are our policies current with the latest SEC guidance on AI use, and do we have audit trail coverage across every AI workflow that touches client data or client communication?
Answer to look for: If the answer is "we think so" rather than "yes, and here's the documentation," that's a gap worth closing.
Layer 5: The organizational layer
This is the layer that determines whether the other four generate any ROI. It's also the hardest to budget for, because most of the costs don't appear on a software invoice.
What lives here: data preparation and hygiene (you cannot get value from AI sitting on top of a CRM full of duplicates and missing fields), change management and training, the productivity dip during adoption, shadow AI usage when employees route around official tools, and the ongoing maintenance of prompts, agents, and workflows as models change underneath them.
AI is closer to an empirical natural science than a deterministic engineering discipline. As Anthropic's Dario Amodei has framed it, working with these systems is more like discovery than construction. You learn by using them, by trying things, and by sharing what works.
That means knowledge tends to silo by individual user. The advisor who has cracked a great client meeting prep workflow rarely shares it across the firm without a forcing function. This is where HR and operations have a meaningful role: creating the structures that let internal learning compound. Without that, you'll spend on the first four layers and watch the ROI evaporate at the fifth.
The CFO question: do we have internal AI champions in each department, and is there a forum for sharing what's working across the firm?
Answer to look for: human capital systems operating with intentional knowledge share, thus maximizing “speed to value” on the overarching AI budget.
In closing, here’s the “CFO’s Back Pocket Handbook” for the questions to ask when AI comes up in budgetary conversations:
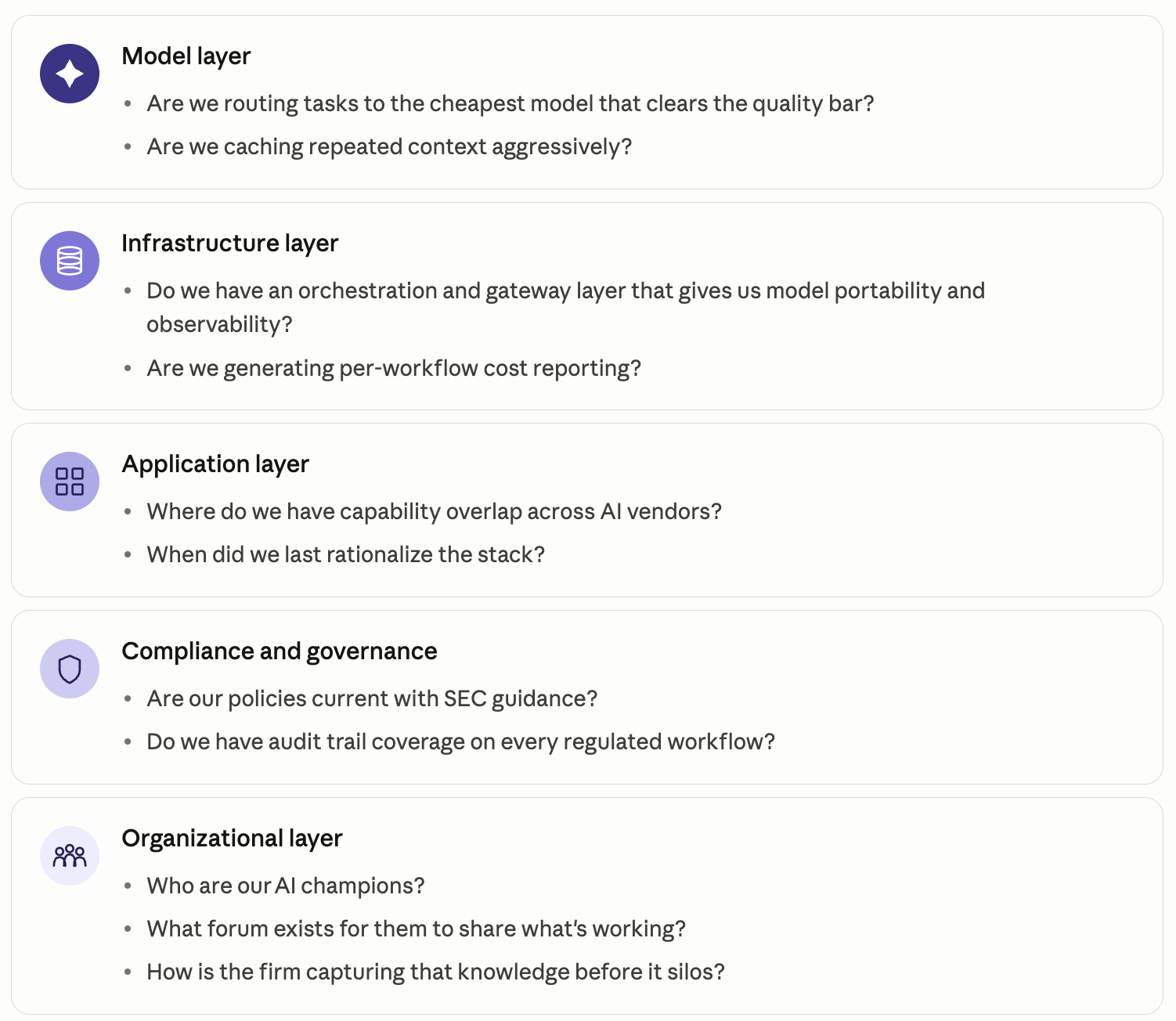
Diagram listing AI cost review questions across the model, infrastructure, application, compliance and governance, and organizational layers.
I hope this has been helpful, and if you’re reading this, feel free to reach out to my colleagues and I at Impruve if we can be of help in diving deeper on any of these layers.
Danny Shannon CTO, Impruve