

Does Our RIA Need a Data Lake? A Practical Guide For RIA Leaders Thinking About Data Infrastructure
About the author - Jordan Campbell is Partner & Chief Data Officer at Impruve. He spent the better part of the past decade leading full lifecycle data, AI/ML, and infrastructure build outs in highly regulated environments deploying enterprise-grade software. Nowadays, he spends his time rolling up his sleeves in tight collaboration with RIA executives on a range of advanced AI projects.
I spend a lot of time talking to RIAs about their data. Most of them come into the conversation fairly anxious. They've been repeatedly told that they need a data lake, their data is a mess, and that, as a result, they're falling behind on AI. The fear is real, but the advice is almost always fairly hollow. Nobody is telling them what to actually do next given the specific problems their firm is facing.
The truth is that your firm may not actually need a data lake. In fact, you might not even need a data warehouse. But understanding what these tools actually do and what specific problems they solve will help you figure out the right path forward for your firm.
This piece won't tell you what you should buy or build. The fact is that I can't, and nobody can, without first understanding your firm. What this piece will do, though, is give you the framework to figure that out for yourself.
My problem with "you need a data lake" is that it’s completely backwards in almost all cases. You're being handed a solution before anyone has asked what the problem is.
Pick one problem in your firm. What data do you need to solve it? Where does that data live today? What specifically is blocking you from accessing it? In most cases, the answer isn't "I don't have a data lake." It's going to be something far more specific (and actionable).
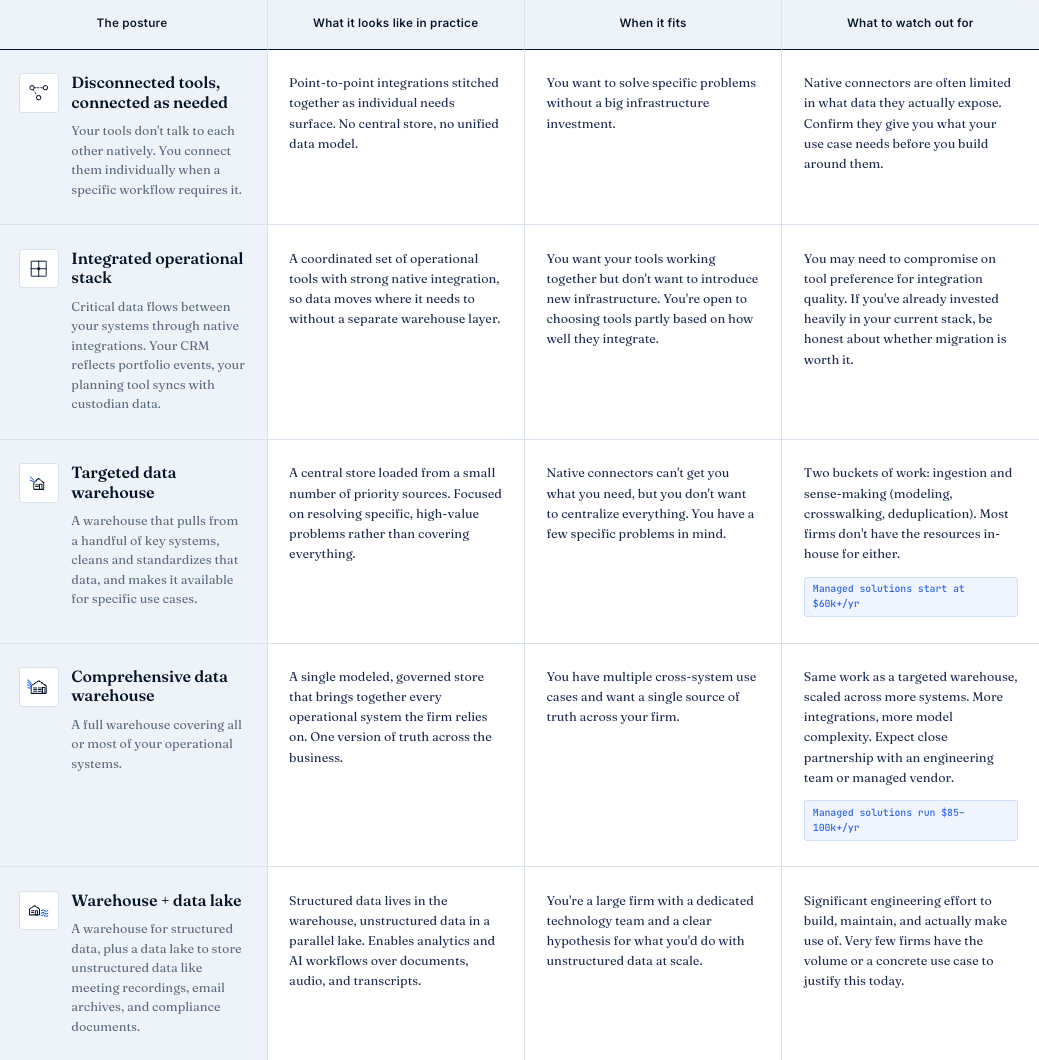
Before we go further, let’s get the terminology sorted out. There are generally three functional layers that make up data infrastructure at an RIA.

These don’t need to be competing choices, and I’d recommend thinking of them as layers. Many firms only need the first two layers, and a lot of what gets marketed as a "data lake" is really just a warehouse.
(There's also a concept called a "lakehouse" that combines elements of both, but again, that’s overkill for many RIA firms today.)
One reason this decision feels overwhelming is that it's hard to know when any of these tools become necessary. There are more options than most people realize, and the right one for your firm depends on what you're trying to accomplish and where your constraints are.
Wherever you sit on this spectrum, the “work” around removing the constraints related to your data doesn't disappear, but it does change form. At one end, the work is in connecting your tools and maintaining those integrations. At the other end, it's in ingesting data, reconciling it across tools, and keeping a warehouse running. There's no version of this where implementing a data warehouse is a “magic bullet” for your data problems; the nature of the work to be done evolves.
Not every use case requires centralizing your data in advance, either. AI agents can increasingly connect to your source systems in real-time to access the data they need at the moment a workflow runs. The MCP standard is making this more practical across a growing number of tools, and for a lot of common workflows like meeting prep, client review assembly, and ad-hoc questions, it works well enough.
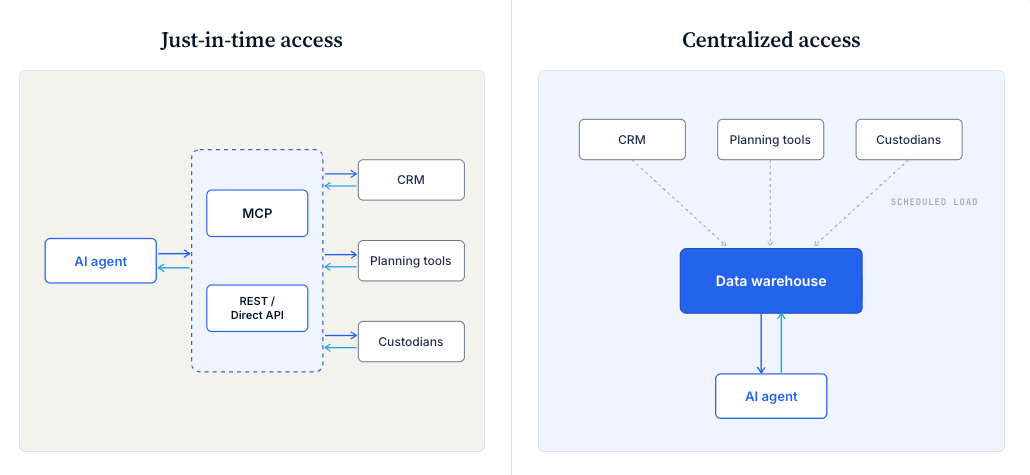
Centralization becomes necessary when you need to combine data across multiple systems on a recurring basis: analytics, trend analysis, or anything that requires historical data or reconciliation between systems. Those workflows need the data to already be somewhere clean and queryable.
So how do you decide where your firm should be?
Start from the problems you're trying to solve. Figure out what's specifically blocking you. And be honest about which tradeoffs your firm is best positioned to take on. Are you better off adapting how your firm works, or the tools you use, to get a more integrated stack? Or would you rather keep your preferred tools and invest in consolidating the data downstream? Both approaches can work, but only you can decide which set of problems you'd rather own.
One more thing worth flagging: there's a real risk in centralizing your data before you have strong processes in place. When a downstream layer is responsible for cleaning and standardizing everything, the discipline to maintain good data hygiene at the source tends to erode. You can transform the format of bad data, but you can't fix what was never captured correctly.
All that being said, your first step is to get clear on the problems you're trying to solve today, the use cases you want to build toward, and what's preventing you from getting started. Everything else follows from that.